2THU
2THU  3SUSTech
3SUSTech  4CUHK
4CUHK  5UW
5UW  6SZTU
6SZTU  7JNU
7JNU 
![]() Click to jump to each section.
Click to jump to each section.
We present Dyn-Bench, a large-scale benchmark for quantitatively evaluating the spatio-temporal reasoning abilities of MLLMs under fine-grained dynamic-object understanding. Dyn-Bench consists of 1k dynamic video scenes with 7k visual question answering pairs and 3k grounding annotations, collected from four 2D video segmentation and four 4D dynamic scene datasets spanning diverse environments, motion patterns, and camera trajectories. As illustrated in Fig. 2, the benchmark is structured into three complementary levels: Dynamic Inter-Object Perception, Dynamic Object-Scene Tracking, and Dynamic Camera-Object Reasoning, each integrating spatio-temporal reasoning and dynamic object grounding tasks. An overview of dataset statistics is provided in Fig. 3.

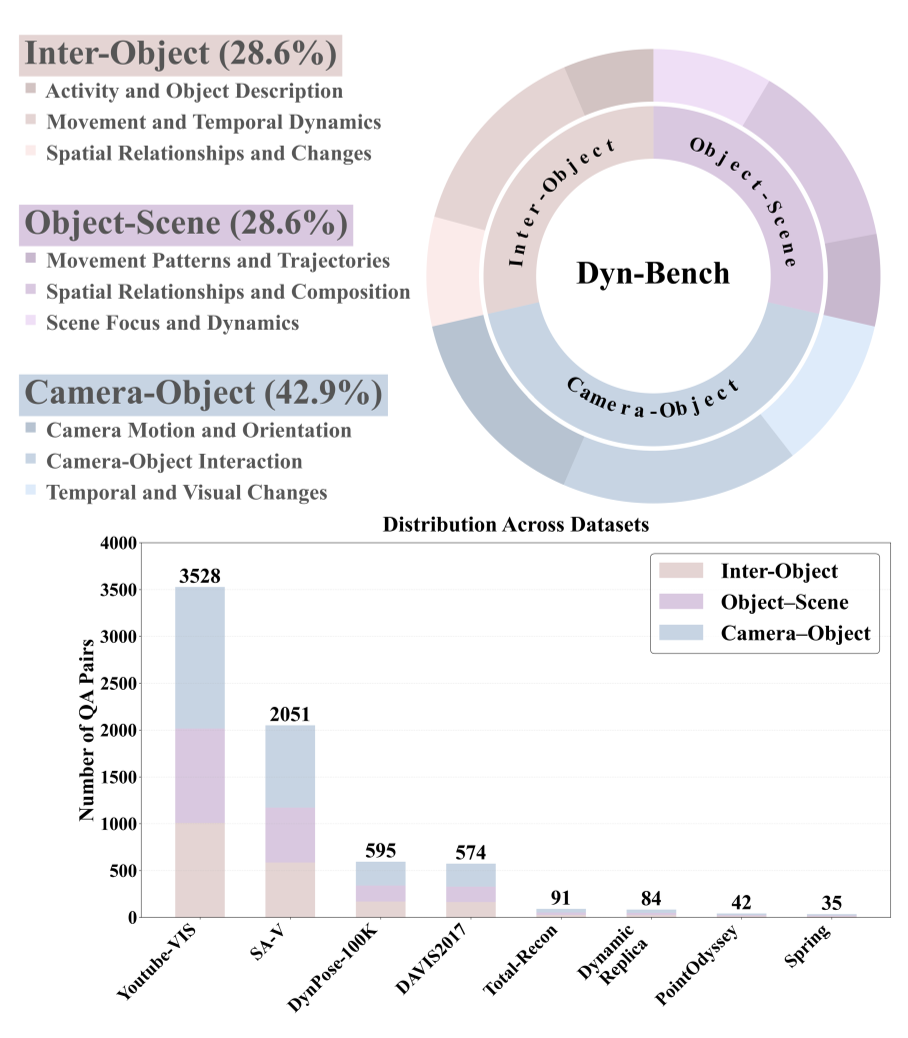
We develop a robust pipeline to construct Dyn-Bench.
1. Data Collection and Filtering: We construct Dyn-Bench by collecting dynamic videos from four 2D video segmentation datasets (DAVIS, SA-V, DynPose-100K, and YouTube-VIS) and four 4D dynamic-scene datasets (DynamicReplica, PointOdyssey, Spring, and Total-Recon). These datasets provide instance masks, depth maps, and camera poses, enabling accurate question-answer generation and object category annotation. Missing annotations are completed using existing pipelines to ensure cross-modal consistency. To ensure data reliability, we employ a multi-criteria data filter strategy assessing geometric stability, motion smoothness, image sharpness, and depth consistency, supported by VLM-based quality evaluation. Low-quality videos are discarded to maintain visual and geometric fidelity. Filtering statistics are shown in Tab. 1.
2. Question-Answer Generation: Based on the filtered video collection, we employ a ST-TCM in conjunction with Qwen3-VL to construct dynamic-object-centered VQA tasks. The benchmark evaluates MLLMs across three complementary dimensions: Dynamic Inter-Object Perception, focusing on how models perceive and interpret motion interactions and spatial relations among multiple dynamic objects (e.g., approach, occlusion, or overtaking); Dynamic Object-Scene Tracking, capturing how individual objects are temporally tracked and evolve within continuously changing scenes (e.g., entering, leaving, or undergoing functional transitions); and Dynamic Camera-Object Reasoning, assessing how camera motion influences the perceived geometry, depth, and temporal consistency of dynamic objects (e.g., relative translation, rotation, or event order). Each VQA dimension is paired with a corresponding object grounding task that associates the referenced dynamic objects with their instance segmentation masks. Dimension-specific prompting strategies and ST-TCM configurations are applied to Qwen3-VL to ensure focused spatio-temporal reasoning.
3. Spatio-Temporal Textual Cognitive Map Construction: To capture fine-grained object motion and interactions in dynamic scenes, we construct a Spatio-Temporal Textual Cognitive Map (ST-TCM) for each filtered video. Given per-frame RGB-D inputs and segmentation masks, 3D object trajectories are reconstructed to obtain geometric attributes such as position, size, and orientation in world coordinates. We then model inter-object and camera-object relations based on spatial proximity and motion continuity, capturing dynamic behaviors such as interaction and relative movement. All geometric and spatial cues are translated into textual descriptions through a rule-based template system, integrating object geometry, motion, and relational dynamics into a unified spatio-temporal representation. This structured textual form serves as input to Qwen3-VL-235B for dynamic object centered visual question answering and grounding. Detailed implementation procedures are provided in the supplementary material.
4. Human Quality Control: To ensure the reliability and perceptual validity of the filtered videos and generated annotations, we conduct an additional round of human verification covering video quality, mask consistency, VQA accuracy, and dynamic object category identification. Annotators assess camera stability, motion smoothness, and scene complexity to confirm visual quality, and examine segmentation masks to verify temporal coherence and consistent object identity across frames. The generated VQA and grounding pairs are also reviewed to ensure accurate object reference, reasoning-level alignment, and consistency with visual evidence. A summary of the multi-stage filtering and verification process is presented in Tab. 1.
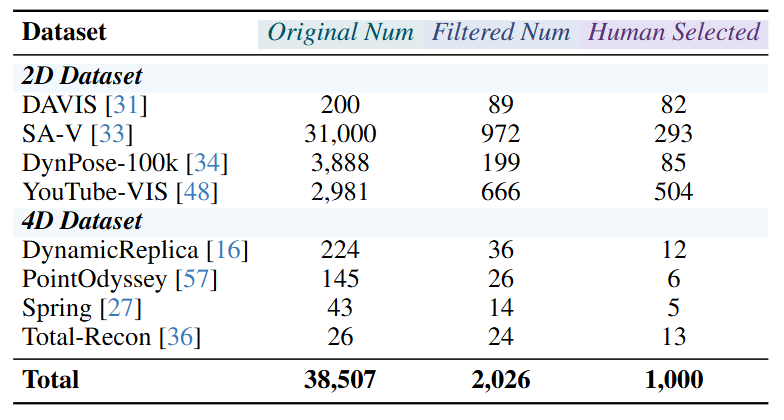
Table 1. Dataset statistics across Dyn-Bench filtering stages.
Benchmark Models. We evaluate three categories of MLLMs: general, spatial, and region-level models. General MLLMs (e.g., GPT-4o, Qwen3-VL) and spatial MLLMs (SpaceR, VST, Spatial-SSRL, SpatialLadder) lack explicit dynamic object grounding and are therefore evaluated only on spatio-temporal reasoning. In contrast, region-level MLLMs (Sa2VA, UniPixel, VideoGLaMM) are assessed on both spatio-temporal reasoning and dynamic object grounding to measure their fine-grained dynamic understanding.
To benchmark performance on spatio-temporal reasoning, we include two chance baselines: Chance Level (Random), obtained by uniformly sampling answers for multiple-choice questions, and Chance Level (Frequency), obtained by predicting the most frequent answer per task. All models are evaluated in a zero-shot setting using their default instruction templates to ensure consistent and fair comparison.
Metric Design. For the three VQA task levels, we adopt a multiple-choice answering format and use Accuracy (ACC) as the primary evaluation metric, following standard practice. ACC is computed by exact matching over the model's selected multiple-choice option.
For the corresponding object grounding tasks, we employ the video object segmentation metric ℐ&ℱ, which averages region similarity (ℐ) and boundary accuracy (ℱ).
Tab. 2 and Tab. 3 report the overall performance on Dyn-Bench, and corresponding radar results are shown across the three VQA levels. Our findings are summarized as follows:
General MLLM. Proprietary models such as GPT-4o and GPT-5 maintain strong performance in spatio-temporal reasoning, particularly excelling in inter-object understanding through accurate modeling of actions and relational dynamics. In contrast, open-source models have rapidly narrowed the gap, with large-scale systems like Qwen3-VL-235B achieving comparable or even superior overall results, and smaller variants such as LLaVA-OneVision-1.5-8B and Qwen3-VL-32B delivering competitive accuracy despite reduced parameter counts. Overall, proprietary models tend to dominate relational and motion-oriented reasoning, while open-source models demonstrate more balanced generalization across object- and scene-level understanding.
Spatial MLLMs. Compared with general MLLMs, spatial models exhibit stronger performance on geometry-dependent object–scene reasoning, highlighting the value of explicit spatial priors. Within this category, VST-7B-RL attains the strongest overall performance, with SpaceR-7B and SpatialLadder-3B following closely. However, despite their strengths in static and relational spatial tasks, spatial MLLMs remain weaker than both general and region-level models on camera–object interaction and motion-centric reasoning, indicating that spatial priors alone are insufficient for modeling dynamic 4D scenes.
Region-level MLLMs. Models in this category deliver the strongest performance on object-centric spatio-temporal reasoning and dynamic object grounding, enabled by their integration of fine-grained regional cues and localized feature alignment. UniPixel-7B provides the best overall spatio-temporal reasoning within this group, while Sa2VA-based variants achieve the highest grounding accuracy across diverse dynamic settings. Relative to both general and spatial MLLMs, these models exhibit pronounced advantages in motion understanding and relational dynamics, indicating that region-level grounding supplies robust structural priors that enhance temporal coherence and support more reliable interpretation of complex dynamic scenes.
| Act. & Obj. Desc. | Move. & Temp. Dyn. | Spatial Rel. & Change | Mov. Patterns & Traj. | Spatial Rel. & Comp. | Scene Focus & Dyn. | Cam. Motion & Orient. | Cam-Obj. Interaction | Temp. & Visual Change | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Methods | Rank | Avg. | Inter-Object | Object-Scene | Camera-Object | ||||||
| Baseline | |||||||||||
| Chance Level (Random) | - | 25.0 | 25.0 | 25.0 | 25.0 | 25.0 | 25.0 | 25.0 | 25.0 | 25.0 | |
| Chance Level (Frequency) | - | 12.3 | 21.6 | 31.5 | 29.1 | 27.7 | 13.8 | 33.5 | 10.1 | 25.6 | |
| Proprietary Models (API) | |||||||||||
| GPT-4o | 3 | 50.1 | 56.1 | 38.7 | 44.6 | 63.1 | 59.1 | 68.8 | 47.2 | 42.0 | 49.2 |
| GPT-5 | 2 | 59.5 | 68.6 | 47.3 | 48.1 | 71.7 | 65.9 | 73.0 | 60.9 | 58.4 | 58.4 |
| Gemini-2.5 Pro | 1 | 59.8 | 69.7 | 48.0 | 50.5 | 67.8 | 59.9 | 65.6 | 60.7 | 54.9 | 51.8 |
| Open-source Models | |||||||||||
| InternVL3-14B | 7 | 53.7 | 65.3 | 47.0 | 49.7 | 67.8 | 69.2 | 77.7 | 37.9 | 44.9 | 46.9 |
| InternVL3-38B | 5 | 54.2 | 68.2 | 44.8 | 48.4 | 71.1 | 67.3 | 76.7 | 41.2 | 48.9 | 44.6 |
| InternVL3.5-8B | 11 | 50.3 | 66.6 | 41.0 | 44.8 | 63.5 | 62.7 | 69.6 | 41.5 | 40.1 | 46.4 |
| InternVL3.5-38B | 10 | 50.8 | 65.0 | 40.7 | 42.4 | 60.2 | 62.3 | 72.3 | 45.5 | 42.9 | 44.6 |
| Qwen2.5-VL-7B | 9 | 51.6 | 61.7 | 42.8 | 48.0 | 69.1 | 67.0 | 73.7 | 43.8 | 39.6 | 42.8 |
| Qwen2.5-VL-32B | 4 | 56.0 | 71.5 | 52.2 | 53.8 | 71.5 | 67.6 | 75.3 | 42.1 | 46.7 | 47.9 |
| Qwen2.5-VL-72B | 8 | 51.8 | 65.5 | 41.1 | 43.7 | 60.4 | 57.8 | 68.3 | 49.2 | 42.6 | 55.0 |
| Qwen3-VL-8B | 3 | 61.4 | 70.8 | 52.6 | 53.6 | 75.0 | 71.2 | 82.4 | 55.4 | 52.6 | 60.0 |
| Qwen3-VL-32B | 2 | 62.7 | 73.7 | 56.2 | 53.4 | 74.6 | 73.1 | 80.2 | 58.2 | 54.3 | 56.9 |
| Qwen3-VL-235B | 1 | 65.3 | 76.4 | 55.8 | 55.6 | 77.8 | 76.1 | 84.1 | 59.8 | 59.0 | 60.2 |
| LLaVA-OneVision-1.5-4B | 12 | 49.9 | 50.5 | 48.5 | 50.3 | 65.2 | 64.8 | 63.9 | 39.9 | 36.6 | 46.1 |
| LLaVA-OneVision-1.5-8B | 6 | 53.8 | 60.9 | 47.7 | 53.4 | 74.4 | 69.6 | 75.4 | 41.0 | 37.0 | 51.6 |
| Spatial MLLMs | |||||||||||
| SpaceR-7B | 1 | 56.5 | 66.6 | 49.2 | 52.7 | 72.2 | 67.8 | 78.2 | 50.3 | 40.0 | 55.5 |
| VST-7B-RL | 2 | 55.7 | 68.6 | 48.4 | 51.9 | 73.0 | 70.7 | 79.4 | 45.1 | 39.1 | 52.9 |
| Spatial-SSRL-7B | 4 | 45.9 | 54.5 | 40.0 | 48.1 | 68.5 | 65.9 | 73.8 | 35.8 | 36.7 | 37.7 |
| SpatialLadder-3B | 3 | 53.6 | 60.8 | 46.1 | 49.2 | 70.0 | 70.9 | 77.1 | 38.2 | 42.0 | 51.9 |
| Region-level MLLMs | |||||||||||
| UniPixel-3B | 2 | 55.4 | 63.3 | 47.2 | 53.2 | 71.7 | 70.2 | 77.7 | 43.2 | 43.6 | 52.0 |
| UniPixel-7B | 1 | 58.1 | 64.4 | 50.2 | 54.7 | 76.1 | 70.4 | 79.7 | 47.3 | 47.3 | 55.7 |
| VideoGLaMM | 7 | 30.7 | 35.6 | 34.4 | 35.0 | 34.6 | 38.2 | 39.3 | 22.7 | 21.2 | 25.9 |
| Sa2VA-InternVL2.5-8B | 6 | 49.4 | 61.0 | 42.4 | 45.7 | 66.1 | 62.8 | 71.9 | 36.6 | 36.4 | 47.2 |
| Sa2VA-InternVL3-14B | 3 | 53.6 | 55.9 | 48.9 | 53.2 | 72.0 | 70.2 | 74.6 | 38.1 | 39.6 | 53.6 |
| Sa2VA-Qwen2.5-VL-7B | 4 | 50.3 | 58.6 | 39.3 | 52.9 | 67.6 | 62.1 | 70.5 | 38.8 | 39.1 | 49.3 |
| Sa2VA-Qwen3-VL-4B | 5 | 49.8 | 60.8 | 39.3 | 46.2 | 67.2 | 62.0 | 73.2 | 41.0 | 44.5 | 36.8 |
| Models | Average | Inter-Object | Object-Scene | Camera-Object | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| \(\mathcal{J}\) | \(\mathcal{F}\) | \(\mathcal{J}\)&\(\mathcal{F}\) | \(\mathcal{J}\) | \(\mathcal{F}\) | \(\mathcal{J}\)&\(\mathcal{F}\) | \(\mathcal{J}\) | \(\mathcal{F}\) | \(\mathcal{J}\)&\(\mathcal{F}\) | \(\mathcal{J}\) | \(\mathcal{F}\) | \(\mathcal{J}\)&\(\mathcal{F}\) | |
| Region-level MLLMs | ||||||||||||
| UniPixel-3B | 40.6 | 41.2 | 40.9 | 37.7 | 38.3 | 38.1 | 45.8 | 46.6 | 46.2 | 38.2 | 38.8 | 38.5 |
| UniPixel-7B | 64.4 | 66.0 | 65.2 | 65.4 | 66.6 | 66.0 | 70.1 | 72.0 | 71.1 | 57.8 | 59.4 | 58.6 |
| VideoGLaMM | 55.4 | 63.8 | 59.6 | 54.8 | 63.0 | 58.9 | 61.4 | 69.8 | 65.6 | 49.9 | 58.7 | 54.3 |
| Sa2VA-InternVL2.5-8B | 74.2 | 77.1 | 75.6 | 75.4 | 77.8 | 76.8 | 78.6 | 81.9 | 80.2 | 68.5 | 71.7 | 70.1 |
| Sa2VA-InternVL3-14B | 70.5 | 74.1 | 72.2 | 72.7 | 76.1 | 74.4 | 74.2 | 77.9 | 76.0 | 64.5 | 68.2 | 66.3 |
| Sa2VA-Qwen2.5-VL-7B | 71.1 | 74.5 | 72.8 | 71.9 | 74.9 | 73.4 | 74.1 | 77.7 | 75.9 | 67.3 | 70.8 | 69.1 |
| Sa2VA-Qwen3-VL-4B | 66.8 | 70.4 | 68.6 | 66.5 | 70.0 | 68.3 | 73.4 | 77.0 | 75.2 | 60.4 | 64.1 | 62.2 |
To investigate how MLLMs think in dynamics textually, we first analyze GPT-4o's self-explanations on failure cases from Dyn-Bench to examine its Chain-of-Thought (CoT) behavior in dynamic settings. We then introduce a spatio-temporal textual context module (ST-TCM) as an auxiliary input to qualitatively assess its effect on reasoning. Finally, we conduct an ablation study on three key components, namely temporal semantics, spatial geometry, and motion dynamics, to identify which factors most effectively enhance spatio-temporal reasoning.
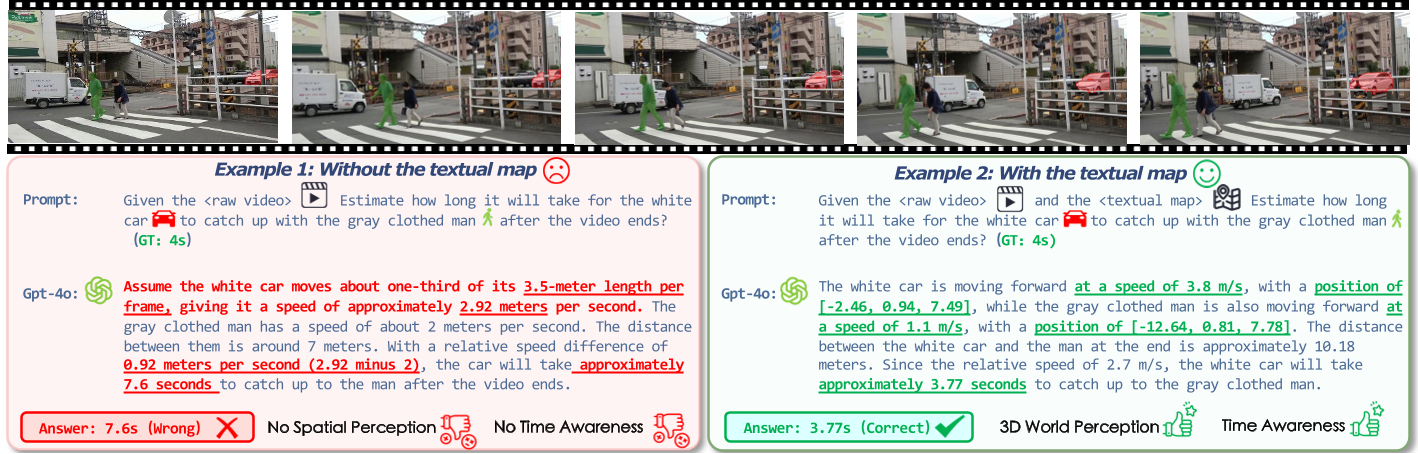
Self-explanation refers to an MLLM's ability to articulate intermediate reasoning while generating responses. We examine GPT-4o's self-explanations on Dyn-Bench and present representative success and failure cases in Fig. 4 to illustrate its reasoning strengths and limitations.
Case Studies. Fig. 4 compares GPT-4o's self-explanations in a failure and a success case. In the failure example (Fig. 4, left), the model generates linguistically fluent but physically inconsistent reasoning. When estimating how a white car catches up with a gray-clothed pedestrian, it relies on visual heuristics such as apparent size change across frames rather than metric reasoning, resulting in inaccurate temporal estimation. This reflects a gap between linguistic coherence and physical grounding. In contrast, the success case (Fig. 4, right) demonstrates structured reasoning that integrates motion and relational cues to estimate relative velocities and produce a temporally consistent prediction. These findings suggest that incorporating explicit spatio-temporal cues enables more coherent and causally grounded reasoning about dynamic events.
Error Analysis. GPT-4o's errors in dynamic reasoning can be broadly categorized into three fundamental types:
These errors indicate that GPT-4o lacks structured temporal, spatial, and relational representations, ultimately constraining its ability to reason about motion in a physically coherent manner.
To further investigate how ST-TCM enhances spatio-temporal reasoning and dynamic object grounding, we conduct an ablation over its three components: temporal semantics (T), motion dynamics (M), and spatial geometry (S). We evaluate two representative models under distinct paradigms: the general MLLM Qwen3-VL-8B for spatio-temporal reasoning and the region-level MLLM UniPixel-3B for dynamic object grounding.
As shown in Tab. 4, incorporating ST-TCM components consistently improves both models, though their optimal configurations differ. For Qwen3-VL-8B, motion and spatial cues (M+S) produce the largest gains, highlighting the role of object movement and geometric structure in achieving stable temporal reasoning, whereas temporal cues alone are insufficient. For UniPixel-3B, motion cues offer the primary improvement, and spatial cues mainly refine object–trajectory alignment. The M-only configuration attains the best overall performance.
| Configuration | Inter-Object | Object-Scene | Camera-Object | Avg | Inter-Object | Object-Scene | Camera-Object | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| \(\mathcal{J}\) | \(\mathcal{F}\) | \(\mathcal{J}\)&\(\mathcal{F}\) | \(\mathcal{J}\) | \(\mathcal{F}\) | \(\mathcal{J}\)&\(\mathcal{F}\) | \(\mathcal{J}\) | \(\mathcal{F}\) | \(\mathcal{J}\)&\(\mathcal{F}\) | |||||
| Qwen3-VL-32B | Sa2VA-InternVL2.5-8B | ||||||||||||
| w/o TCM | 59.0 | 76.7 | 56.2 | 62.8 | 74.8 | 76.6 | 75.2 | 78.4 | 81.7 | 80.0 | 70.3 | 73.5 | 71.9 |
| w/ T only | 59.3 | 76.4 | 56.3 | 62.9 | 76.6 | 79.3 | 78.0 | 79.7 | 82.9 | 81.3 | 73.0 | 76.1 | 74.6 |
| w/ M only | 64.3 | 77.1 | 53.5 | 63.3 | 76.8 | 79.6 | 78.2 | 79.7 | 83.0 | 81.4 | 73.8 | 77.3 | 75.5 |
| w/ S only | 66.1 | 78.7 | 60.1 | 67.2 | 76.9 | 79.7 | 78.3 | 79.9 | 83.2 | 81.5 | 74.8 | 78.5 | 76.4 |
| w/ T + M | 63.8 | 76.7 | 54.0 | 63.3 | 77.0 | 79.8 | 78.4 | 79.8 | 83.1 | 81.4 | 73.8 | 77.3 | 75.5 |
| w/ T + S | 67.0 | 78.5 | 59.6 | 67.1 | 76.9 | 79.7 | 78.3 | 80.0 | 83.3 | 81.8 | 74.9 | 78.6 | 76.7 |
| w/ M + S | 68.4 | 78.8 | 59.4 | 67.5 | 77.1 | 79.9 | 78.5 | 80.1 | 83.5 | 81.6 | 75.3 | 78.9 | 77.1 |
| w/ T + M + S | 69.2 | 79.1 | 60.5 | 68.3 | 77.3 | 80.2 | 78.8 | 80.2 | 83.6 | 81.9 | 75.4 | 79.1 | 77.3 |
To examine how MLLMs think in dynamics visually, we conduct qualitative and quantitative analyses to study how explicit visual guidance affects motion understanding. As shown in Fig. 5, we design two input strategies to guide model attention toward dynamic regions.
These strategies explicitly ground visual perception in motion-centric regions, enhancing spatio-temporal alignment and relational reasoning. We evaluate Qwen3-VL-8B under these configurations, using the Raw Video setting as baseline.
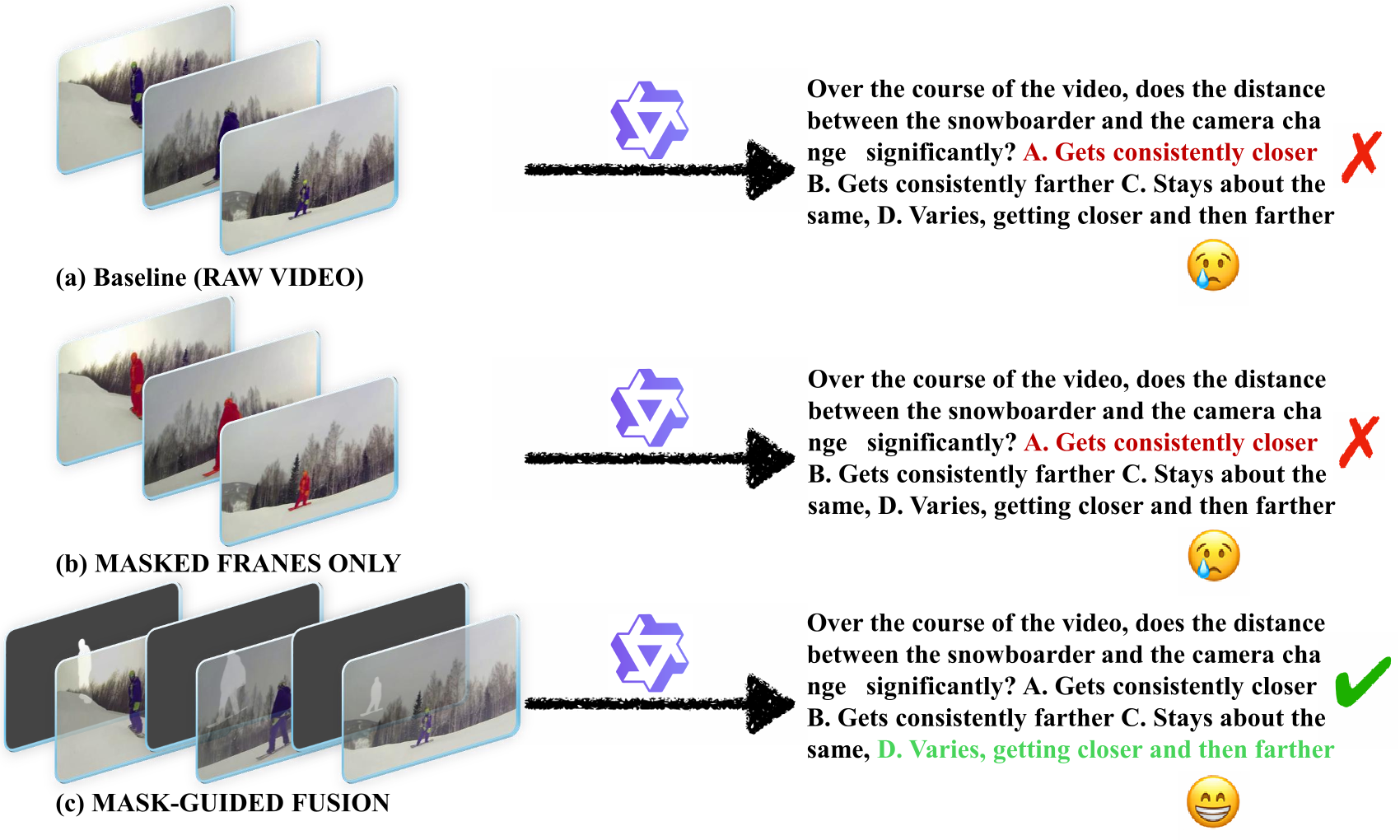
The results in Tab. 5 show that mask-guided visual grounding enhances the model's ability to capture dynamic object interactions and maintain temporal consistency. Masked Frames Only offers only minor gains, suggesting limited value from isolated localization cues. In contrast, the Mask-Guided Fusion setting improves all categories, with the largest gains in Inter-Object and Camera-Object reasoning, which demand fine-grained motion and relational understanding. These results show that integrating appearance and motion cues strengthens object grounding and yields more coherent spatio-temporal reasoning.
| Configuration | Inter-Object | Object-Scene | Camera-Object | Avg |
|---|---|---|---|---|
| Raw Video | 38.9 | 74.5 | 55.6 | 53.8 |
| Masked Frames Only | 39.4 | 74.3 | 54.9 | 53.8 |
| Mask-Guided Fusion | 41.8 | 77.0 | 60.0 | 57.1 |
We study how MLLMs think in dynamics by introducing Dyn-Bench, a comprehensive benchmark designed to evaluate both object-level and scene-level spatio-temporal reasoning and grounding across three representative model categories: general, spatial, and region-level MLLMs. Through this dual textual–visual assessment, we provide a systematic examination of how models perceive, track, and interpret dynamic content in the physical 4D world, including their ability to capture motion patterns, maintain temporal consistency, and model multi-entity interactions.
Our experiments show that the Spatio-Temporal Textual Cognitive Map substantially enhances temporal coherence and relational reasoning by imposing structured linguistic abstraction over dynamic events, while mask-guided visual grounding further strengthens motion perception, improves fine-grained object continuity, and mitigates temporal drift. Taken together, these findings suggest that reliable dynamic understanding in MLLMs emerges from a synergistic coupling between high-level temporal semantics and localized region-level grounding.
Looking ahead, future spatio-temporal MLLMs should integrate dynamic-object perception and temporal reasoning more tightly, motivating unified architectures that jointly model motion dynamics, relational structure, and higher-level temporal cognition to achieve more coherent, physically grounded reasoning in complex and continuously evolving environments.